

How To Change Frequency Of "Low Disk" Message
Alarm GOVERNANCE: How do I manage my alerts such that I am not overwhelmed?

| | One of the virtually common problems when configuring Geneos (or whatsoever monitoring tool for that matter) is ensuring that the users are told when things are going wrong and activeness is required, that alerts are non missed and maybe more chiefly that imitation alerts, or alerts which are non actionable, are minimized or removed completely. "One of the most common mistakes when monitoring is to alarm on likewise many things, once the number of alerts exceeds what is manageable, you are essentially not monitoring at all" While on the confront of it this seems obvious, its substantially difficult to achieve, and requires constant tweaking and change to go along information technology tuned to a changing surround. This article aims to talk through:
In truth you could write a book on this subject area, then this page cannot really be considered comprehensive, only it is a start, and will exist supplemented over time. Equally it stands the following content exists:
|
| | Common Mistakes in the monitoring space |
| | Frequency of Alerts Managing the frequency of alertsCore to the philosophy of good monitoring is that under normal BAU conditions: 1) Alerts are reported at an appropriate level of severity 2) That teams human action within an advisable fourth dimension scale to those alerts three) That no significant alerts are missed 4) Alerts occur at a manageable level Manageable levels ways the team responsibility for the systems tin go along up with the alerts (the number of un-actioned or suppressed alerts exercise not grow over fourth dimension). Appropriate level essentially means that:
|
| | Identifying False Alerts Identifying imitation alertsWhen trying to go alerts to a manageable level you need to get a handle on why the warning levels are high, this includes their frequency and their severity. For example it is by and large more acceptable to have many more warnings than critical's. Alerts tin therefore exist false positives if they do not crave action or suggest action is required more quickly than is actually required (its critical rather than warning for example). The following are some mutual imitation positives:
Inappropriate Severity: Fifty-fifty if the frequency of alerts seems workable, if the squad are getting dozens of disquisitional alerts a week then this peradventure indicative of some very unstable systems that are having a significant impact on the business organization, or poorly configured monitoring. The simplest fashion to call back virtually what severity level a given alarm should be at is how long you will tolerate that situation before interim. In rough terms:
In all cases an activity is divers as something which reduces the severity level, therefore buys you lot more than time, or resolves the state of affairs completely. |
| | Embedding Skillful Noesis Embedding Practiced Knowledge (removing generalizations)Really effective monitoring for whatever given system requires expert knowledge of that system, and a solid agreement of how information technology behaves 'ordinarily'. In comparison to a automobile, noesis of that brand and model will prove a good understanding, but each specific instance of that car will accept its own nuances, the person that drives that machine regularly is best placed to know what normal looks similar, and when things are going wrong or unusual. The deployment of general monitoring is therefore a expert start, but really effective monitoring needs to exist tweaked for that specific case. Not performing these tweaks is a common source of false alerts. The experts, like in the car analogy, are those people that nourish to the system on a regular basis, this may be the development teams that designed it, the support teams that back up information technology, the end users, or more probable a combination of these teams. Examples of specific tweaks for a specific application might include embedding logic into the monitoring to include its observable problems when nether load (High CPU, High Mem, wearisome throughput, Dropped trades etc), The effect on the app of downstream and upstream applications misbehaving, The time information technology takes a to start up and its observable states during that start upward, and what normal looks like and and then on. The process besides requires an good in monitoring, someone that knows what effective monitoring looks like, and what the selected tools tin can and cannot do. Both the arrangement expert and the monitoring adept also demand a solid understanding of who the monitoring is aimed at, since the blazon of information gathered and compiled will vary. For example the data provided to a back up tech will differ from that presented to an Exec. |
| | Ensuring responsibility for constructive monitoring The need for constant maintenanceEffective monitoring requires abiding maintenance, for example:
If this maintenance is not performed then faux alerts will creep in. Within your organisation responsibility for the health and improvements of the monitoring must be conspicuously defined and aggressively implemented. High quality monitoring will in plow enforce high quality processes and systems in the teams and the systems it monitors. The bigger goal is a zero tolerance to on-going alerts, this requires non only proficient tools but cultural alter, which is far more challenging than tweaking configuration. |
| | Less vs More Target the monitoringGeneos is capable of monitoring an enormous multifariousness of systems, and if in that location is nada out of the box, then it can normally exist written in the more generic plugins such as the Toolkit, SQL Toolkit or API Plugin. When deploying monitoring the designers therefore take to elect how much of the systems they will monitor, and exactly what - of all the things they could - they will monitor. There are 2 ends to this scale:
and anything in between. Both approaches have their merits, but in the context of manageable alert levels the latter approach has the best take chances of success. Starting with simply the critical systems also helps embed a culture of timely reaction to alerts into the teams, and allows a zero tolerance approach to critical's, and in the nigh mature teams warnings. Having achieved this culture adding new monitoring while maintaining quality monitoring and process is fairly straight forward. Conversely If y'all start from the outset with a large real estate generating unmanageable or inappropriate (severity) alert levels then this can be a difficult situation to recover from. The teams who adopt the monitoring quickly become acclimatized to abiding alerts and simply use the monitoring as a reactive analysis tool. In some cases at that place is a fear within the organization that turning off or downsizing the monitoring might effect in a missed warning, when in reality they are shut to this state of affairs already. |
| | Actually getting alerted Actually getting alertedAnother important factor in alarm governance is the actual mechanism that you nominate to be alerted. Examples in Geneos include but are non limited to:
The choice of notification method can be significant when considering the concept of 'False Alert', or to put it another way exceeds what is manageable (as well as right). For example if a system is generating 100 critical alerts a day, and the chosen method of displaying those alerts is to show them in the console for as long as they are on-going, and have them clear when that state of affairs ends, that might exist accounted (while not ideal) workable. If on the other hand if an E-mail was generated each time an alert occurred the same number of alerts might overwhelm and desensitize the effected team (100 E-mails is bordering on spam). Consider also that the alerts will non 'be removed' when the situation is fixed since the nature of a mail is that information technology is non-mutable, in a worse case there may exist a 2d mail service for each event to say the situation has been resolved which the user will have to correlate. So the choice of alerting mechanism is significant. Of the examples listed to a higher place they all have different pros and cons, and capabilities.
Context sensitive In a monitoring system of any calibration, it is probably as well true that there volition not exist a 'one size fits all' alerting machinery. In much the aforementioned way equally mode as constructive management of alerts requires customization to the specific behaviors of the monitored app, and so the alerting requires specific tailoring to the intended audition of the alerts. Designers of a monitoring system should pick and choose whats is appropriate, working with the teams involved to ensure they will both meet and act on the alerts when they are generated. For example in a squad that is already saturated with Due east-mails from other systems and their working environments, even if the monitoring organisation generates just a few disquisitional alerts a week, they may be missed due to these external factors. Escalation Escalation is desirable where alerts are non being actioned within the agreed time scales. Consideration needs to be given to what alerting mechanism is used for the escalation. While i on i hard a uncomplicated alter of severity is a form of escalation (assuming at that place is room for maneuver and you are non already crimson), then is a change of alerting type and audience. A mutual process for example (though non automatically the all-time) would be to show a cherry on the console for a time, then send a mail to an individual or group of individuals if that situation persists. A change of alerting type is probable in the case of escalation, since by definition the previous method has non worked. The same intendance and attention needs to be taken when considering escalation alerting types, if not more so given its probable to become to more senior resource who piece of work in different locations and take a dissimilar focus. |
| | Specific things you can practice in Geneos to solve the common monitoring mistakes |
| | The available severity levels Available Severity levelsBefore going into particular on the options for managing alerts its important nosotros highlight the available severity levels . At that place are 4 in Geneos, these also take associated numeric values and colours
|
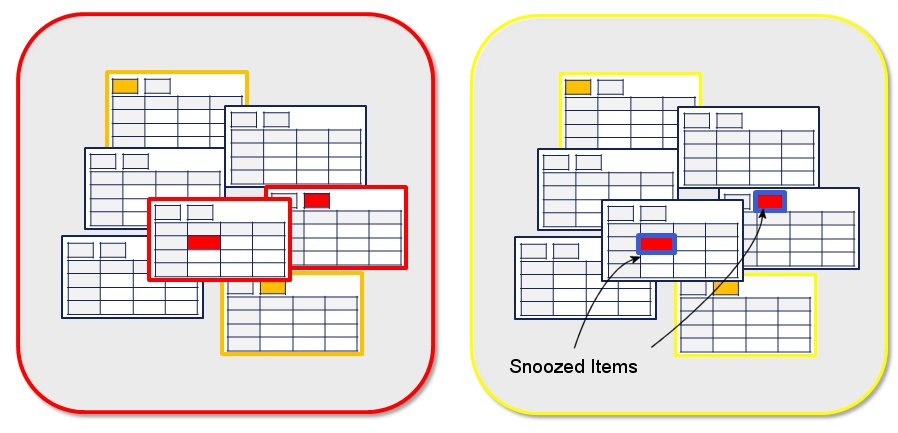
| | Snoozing Snoozing - manually disabling alertsAny data item tin can exist snoozed in Geneos. Past a data detail nosotros mean any of a Gateway, Probe, Entity, Sampler, Dataview, Tabular array cell or Headline. Snoozing has just ane effect: "Snoozing stops the propagation of severity from that information item to its parent" It does non effect the severity of the data particular you take snoozed, so for example in the screen shot below you can see a cell with a disquisitional severity has been snoozed. This ways it will no longer propagate its severity to its parent (the Data view). Because this was the only critical cell in the data view the data view'south severity becomes OK. However the cell remains of critical severity. The deed of snoozing an particular is manual, I.E an operator makes a conscious decision to suppress an alert. At the betoken of snoozing they tin can elect an get out status for the snooze to end. If you review the screen shot above yous tin run across examples of leave conditions in the snooze menu. Past default the menu includes the 'Manual' option, which means it tin can only exist removed by an operator. There are plenty of legitimate reasons to snooze alerts, for case:
Managing snoozesThe danger of any system which allows manual suppression of alerts (for capricious fourth dimension scales or without planned or reasonable go out conditions) is that operators use snoozing as a mechanism to handle being over whelmed by alerts - or in brusk - they snooze everything. As should be obvious this is non a skilful strategy for dealing with excessive alerts and should be activeness discouraged. Snoozed items should therefore be activity managed. There are a number of tools in Geneos that will help with this. Snooze Dockable You tin add together a view to the console that displays a list of all the snoozed items. The view below will show all the snoozed cells and managed entities in the connected gateways Snooze View.ado The paths that drive this view notwithstanding tin exist quite expensive since they expect at all cells all the fourth dimension. Gateway Snooze data view Inside the gateway itself you can add together a Gateway plugin that lists all the snoozed items, the XML for the sampler is below Rules and alerts can be set on this data view every bit normal, allowing users and managers to track snoozes in their organization. Information technology includes a cavalcade on the 'Snooze Blazon' which helps identify what leave criteria users are selecting for the suppression of Alerts via snoozing. Stopping manual snoozes You every bit an system may decide that information technology is never appropriate to employ the snooze command without a valid go out criteria, in which case you tin can apply the security settings to actually remove this option for selected users. Taking business relationship of snoozes in actionsBy default if a data particular or any of its ancestors are snoozed and so Actions run within rules will not fire. This setting is defined under the Advanced section of the Activeness definition in the setup. You tin be more explicit by adding it in the rule block itself. For example: Note nevertheless the rule higher up would non accept account of the cells ancestors (for example the Managed Entity information technology is on) |
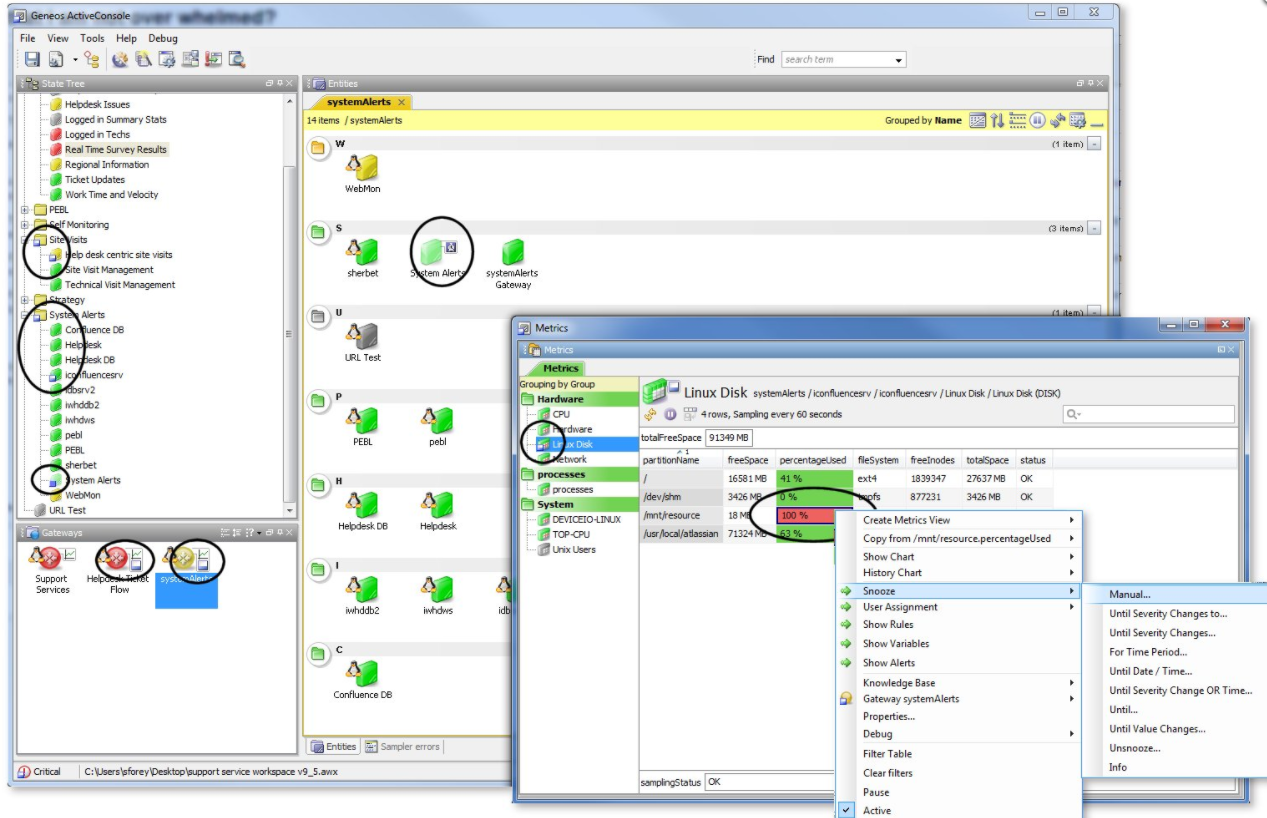


| | Programmatically disabling monitoring Active vs inactive monitoring - automatically disabling monitoringEvery data particular in Genoes likewise has an 'Active'condition, by default all data items are Active, if they are made inactive then they practise not propagate their severity to their parent (in the same way as snooze blocks severity propagation), thus; "An Inactive condition stops the propagation of severity from that data item to its parent" Unlike Snoozing a information detail, which is a manual action, irresolute the active status is performed programatically. The severity of the data item is not inverse, so if a cell, is disquisitional, it remains critical, it only does not influence the severity of its parent. There are two main methods to set an particular inactive: Inside a rule blockY'all tin can set the Active Status of a data item explicitly within a dominion block as a literal, for example: The XML for the higher up rule would be of the form Active TimesWhen because alerting, its often relevant to as well consider whether the systems are expected to be operational at whatever given signal of the day, month or year. Alerting outside these time can generate unnecessary noise, to the responsible team, or others who maybe in another time zone. In Geneos designers tin can use Agile times to suppress alerts during downtime. An Active time can exist set up within the gateway setup, and used in a number if places, one of the most common is in rules: In the in a higher place example an active fourth dimension is used explicitly in the rule block, and in the 2d instance (on the right of the figure) in the rules active fourth dimension settings. In the case of the rules active fourth dimension setting, the whole rule would only be active when within that active time. When referencing active times within the body of a dominion nosotros tin be more granular. Since severity is Just defined by rules, when a rule is outside active fourth dimension information technology would not be setting severity, which would, in upshot, suppress an alert. An example of the dominion is provided below. And hither is the active time XML for a sample working day
|


| | Alerts with more complex Signatures Working with more complex alarm weatherOftentimes an warning situation is more than complex than the designer builds into their monitoring, the simplistic signal value case tin can triggered more than frequently than the actual alert status which is affecting the business. Examples include:
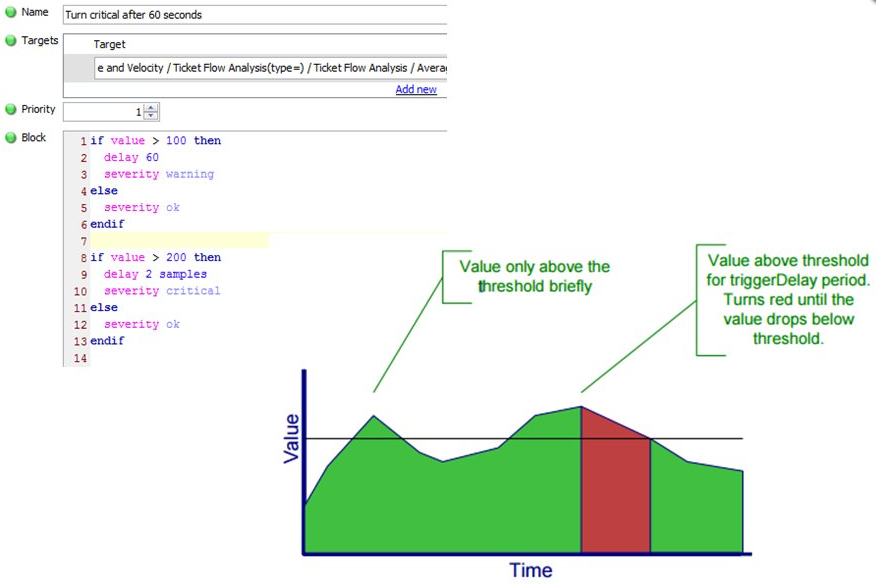
Using DelaysA filibuster tin can be congenital into a rule transaction, it stops the residual the transaction from occurring until that filibuster has passed, and the original condition has remained true. They are useful for weather which may self correct. For instance a CPU has gone over ninety% and stayed above 90% for threescore seconds. An example can be seen below. The delay can be specified in terms of seconds
or samples, thus if the sample time was 20 seconds, 20 samples would be 40 seconds.
Some other example is a process that has an automated restart script, such that if it goes down it is restarted. In this case, the fact that information technology has failed is of involvement, but its non an alarm until the restart has as well failed. In the dominion below we are looking at a procedure plugin, and expecting there to be a unmarried instance. We take added an Action to the gateway which, should Geneos detect that the process count is 0, will try and restart the process automatically. The rule will trigger the restart, and turn the cell Warning while the restart is being performed. If the restart is successful and the instance count goes back to 1 the cell will become 'OK'. If the process count stays 0 for sixty seconds, then the cell will turn Critical - its a genuine Alert that requires activeness. In the example above we are still generating a alert alarm for the elapsing of time that the process is down, fifty-fifty though we expect it to recover without human being intervention. We could choose to be aggressive in limiting alerts by not generating the warning alerts, and simply assuming that recovery of this procedure is part of BAU. We could besides consider utilizing the OK and Undefined serverities a little more than. For example accept the cell be undefined when the case count = ane (I.E. everything is fine, there is nothing of interest), so have it turn OK during the restart process. I.E. everything is OK, simply just an FYI that a restart is underway. This use of the Undefined severity as a valid state for 'Everything is OK' tin help extend the use of the severity levels in Geneos, assuasive OK to be used as an 'Of interest, but not yet a warning level' Employ of History Periods for more than temporal alerting vs point valuesWhile the filibuster function is useful for detecting extended periods of a selected country it suffers in that, if the condition is not true, fifty-fifty for a short time and so the delay is reset. For example a server may exhibit high CPU for a number of minutes, only have cursory periods where information technology drops below the selected threshold. Or an auto restarting process may restart many times in a short period. Both of these may be valid alarm states, merely will not be detected by the 'delay' method. If we consider the car restarting use instance, lets say that equally well equally detecting when it fails to come up, nosotros are too interested if it restarts 5 times (or more) in one hour. Nosotros can achieve this by monitoring the 'Average Case count' over the hour. If it never goes down this should exist one. Anything below one means at least 1 restart occurred. Assuming the restarts are working and the sample fourth dimension of the procedure sampler is 20 seconds, then any Boilerplate below 0.972 means at to the lowest degree 5 restarts occurred, or the process was downwardly over multiple samplers - both worthy of attention.
There a few steps nosotros need to take to set up this up in Geneos ane) Create a history period for the selected time, this goes in the rules department of the setup, the example XML is below <calculationPeriod> 2) We also demand to add an boosted column in the selected process sampler which will retain the average instance count, this is added via the Avant-garde tab of the sampler, an example is shown below iii) finally y'all demand to ascertain a rule, that will both summate the Average example count, and set up severity under your chosen conditions. In this particular rule the severities accept been graded, such that:
|


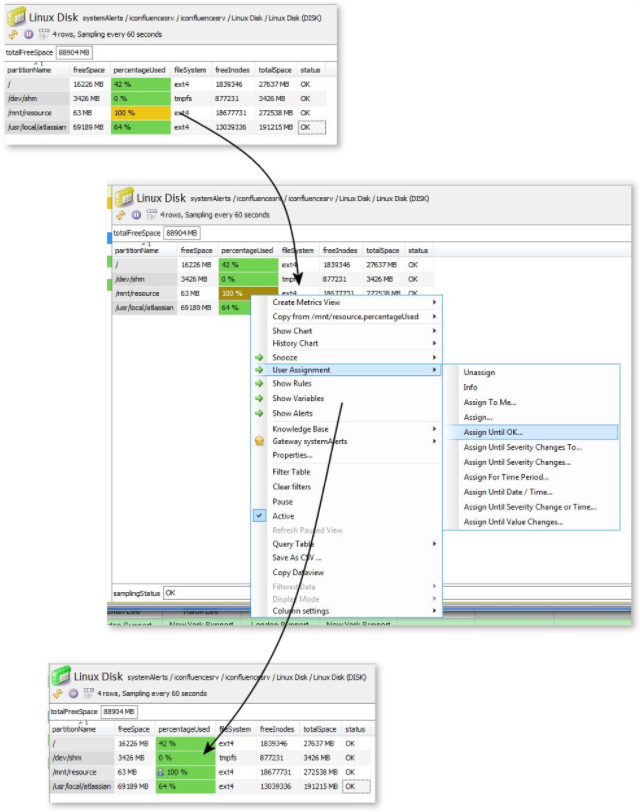
| | User Assignment User AssignmentIn the result that an alert has occurred which requires action within some time calibration (mostly therefore warning and critical) it is likely that a squad member will pick it up for review. Once this has occurred in that location maybe a example for downgrading the alarm. In much the same was as snoozing a cell. The designer of the monitoring can apply the human activity of user assignment within their rules to change the land of the organization. Any data item tin be assigned (then Gateways, probes, manged entities, samplers, information views, tabular array cells and headlines). The act of assigning a user has no default bear on on the severity of a data item unless the rules are designed to have it into account. For instance the dominion shown below will turn the prison cell warning. If it is assigned it will turn OK with the assignment icon to mark that it is existence dealt with. <dominion name="Known Issue"> This would take the following effect: If you do choose to use user assignment as a mode of dealing with alerts, it may also be of interest to track what is and what is non user assigned within your environment. Similar the monitoring of snoozes their is a gateway plugin that tracks snoozes in a organisation. The view includes the number of minutes that the data item has been assigned, so yous tin can include rules to expect for items that have been assigned for extended periods. The XML for the sampler tin be institute below <sampler name="GW User Assignment Data"> Notation that unlike snooze, User assignment does not accept other indicators in the likes of the land tree and Entities view. You tin can likewise create a list view within the console that shows the list of assigned items. User Assigned Items.ado When an item is user assigned the operator can select an exit condition for the assignment. For instance, until the severity changes, a date and time or duration, or until the value changes. There is also a simple assignment with no automatic exit condition, you as an arrangement may make up one's mind that it is never appropriate to utilise the user assignment command without a valid exit criteria, in which case yous can use the security settings to actually remove this option. |


- Tags:
- csh_101
Related articles
- Can I run Geneos in the cloud and on containers ?
- How to prepare Notifications in Active Console?
- Geneos - Email Alert not Received or Delayed
- How exercise I compare dates in a rule?
- Geneos - Rule is not working with variables

Source: https://support.itrsgroup.com/hc/en-us/articles/115004022685-ALERT-GOVERNANCE-How-do-I-manage-my-alerts-such-that-I-am-not-overwhelmed-
Posted by: quinnoloplath.blogspot.com
0 Response to "How To Change Frequency Of "Low Disk" Message"
Post a Comment